
.svg)


알라미 다운받기


AI 코딩 어시스턴트를 쓰다보면…(좋은 의미의) 충격을 받습니다.
이 정도 수준이면 개발 방식이 완전히 바뀌겠는데?라는 생각이 들어요.
자연어로 요구사항을 설명하면 단번에 코드가 생성되고, 오류 메시지를 붙여 넣으면 원인을 짚어주고, 테스트 코드를 작성해달라고 하면 기본 골격이 몇 초 만에 나옵니다. 예전 같으면 공식 문서를 뒤지고, 예제 코드를 찾고, Stack Overflow와 GitHub 이슈를 오가며 감을 잡아야 했던 작업들이 훨씬 짧은 시간 안에 초안으로 만들어집니다.
스켈터랩스 개발팀이 AI 코딩 어시스턴트를 본격적으로 사용하기 시작한 건, 국내 A IT 대기업 프로젝트가 시작되던 시점이었는데요. 개발자는 기존에 익숙하지 않았던 개발 언어를 사용해야 했고, 동시에 MVP를 빠르게 만들어야 하는 상황에 놓여 있었습니다. 다행히 외부 PC 반입이 가능한 환경이었기 때문에, AI 코딩 어시스턴트를 실전 프로젝트에 본격적으로 적용해볼 수 있었어요.
하지만 프로젝트가 커지고 복잡해지자 한계가 드러났습니다.
이번 글에서는 바이브 코딩으로 빠르게 시작했던 개발 방식이 어떻게 Rules, Sub-Agents, Skills로 작업을 구조화하고, Guardrails와 HITL 체크포인트로 품질과 위험을 관리하는 하네스 구조로 발전했는지. 그리고 왜 앞으로의 AI 개발에서 중요한 것은 프롬프트를 잘 쓰는 능력을 넘어 AI가 일할 수 있는 시스템을 설계하는 능력이 되는지 살펴보려 합니다.
0장. 하네스(Harness) 란?
이 글에서 말하는 하네스(Harness)는 AI가 안정적으로 일할 수 있도록 만든 작업 구조를 뜻합니다.
(비슷하진 않지만ㅎㅎ)자동차로 비유해볼까요? 모델이 엔진이라면, 하네스는 핸들, 브레이크, 계기판에 가깝습니다. AI가 코드를 생성하는 능력 자체도 중요하지만, 실전 프로젝트에서는 그보다 더 많은 것이 필요합니다. 어떤 규칙을 따라야 하는지, 어떤 변경은 멈춰야 하는지, 어떤 검증을 통과해야 하는지, 어디서 사람이 확인해야 하는지가 정해져 있어야 해요.
그래서 하네스는 AI를 제한하기 위한 장치라기보다, AI에게 더 많은 일을 맡기기 위한 장치에 가깝습니다. 믿고 맡기려면, 먼저 안전하게 일할 수 있는 환경을 만들어야 하기 때문입니다.

1장. AI 코딩 워크플로우 설계하기
바이브 코딩의 한계는 코드가 아예 동작하지 않을 때보다, 오히려 그럴듯하게 동작할 때 더 잘 드러납니다. 그런데 자세히 들여다 보면 프로젝트의 규칙과 어긋나 있는 경우가 아직은 많습니다.
국내 A IT 대기업 프로젝트에서도 비슷한 일이 있었는데요. 프론트엔드에는 이미 공통 디자인 시스템과 스타일 프레임워크가 있었고, 화면을 구현할 때는 그 기준을 따라야 했습니다. 개발자 입장에서는 AI도 당연히 기존 공통 컴포넌트와 디자인 가이드를 참고해 구현할 것이라고 생각했어요. 코드 리뷰도 통과했기 때문에, 처음에는 큰 문제가 없다고 봤습니다.
그런데 까놓고 보니 일부 코드는 공통 컴포넌트를 잘 사용하고 있었지만, 또 다른 일부는 자체 스타일과 마크업으로 구현되어 있었습니다. 겉보기에는 비슷했기에 사용자 입장에서는 크게 다르게 느끼지 못할 수도 있지만, 내부 구현은 달랐어요. 공통 컴포넌트를 써야 할 자리에 별도 마크업이 들어가 있었고, 디자인 시스템 토큰을 써야 할 곳에 임의의 스타일이 섞여 있었습니다.
이런 애매한 코드는 지금 당장 화면을 깨뜨리지는 않습니다. 그래서 더 문제가 되는데요. 시간이 지나면 유지보수 비용으로 돌아오기 때문입니다. 같은 역할을 하는 컴포넌트가 여러 방식으로 구현되고, 스타일 기준이 흔들리고, 나중에 수정할 때 어디를 고쳐야 하는지 추적하기 어려워지기도 해요.
프로젝트가 커질수록 매번 프롬프트로 모든 맥락을 설명하는 방식에는 한계가 생깁니다. 어떤 규칙은 반복해서 적용되어야 하고, 어떤 변경은 애초에 시도하기 전에 멈춰야 합니다. 어떤 작업은 바로 구현으로 들어가면 안 되고, 먼저 계획부터 검토해야 합니다.

이쯤 되니 AI 코딩 워크플로우가 필요해졌어요.
처음에는 단순했습니다. 계획을 세우고, 코드를 작성하고, 코드 리뷰를 하는 정도였는데요. 이 정도만 해도 아무 계획 없이 바로 구현하는 것보다는 나았어요. AI가 무엇을 만들고 있는지, 어떤 방향으로 수정하고 있는지 최소한의 흐름은 확인할 수 있었기 때문입니다.
그런데 시간이 지나면서, 코드 리뷰만으로는 잡히지 않는 문제가 보이기 시작했습니다. AI가 작성한 코드의 문제가 아니라, 그보다 앞선 계획의 문제였습니다. 기존 구조를 충분히 반영하지 못한 채 변경 범위를 잡거나, 실제로는 건드리지 않아도 되는 영역까지 수정 계획에 포함하는 경우가 있었던 거죠.
이런 문제는 코드 리뷰 단계에서 발견되기도 했지만, 늦으면 배포 이후에야 드러났습니다. 결국 다시 수정 개발을 해야 하는 일이 생겼고요. 그래서 구현 전에 계획 리뷰 단계를 넣었습니다. 바로 코드를 쓰게 하는 대신, 먼저 계획이 맞는지 확인하는 과정입니다. 변경 범위가 적절한지, 기존 구조와 충돌하지 않는지, 빠뜨린 의존성은 없는지 보는 단계였어요.
결국 기능 개발 흐름은 기능 개발 계획 → 계획 리뷰 → 테스트 코드 작성 → 메인 코드 작성 → 코드 리뷰 및 리스크 평가로 정리됐습니다.
2장. AI에게 규칙 알려주기
AI가 프로젝트 규칙을 어기는 이유는 단순합니다.
그 규칙을 모르기 때문입니다.
사람 개발자는 코드 리뷰, 회의, 과거 장애 사례, 팀 내 관습을 통해 자연스럽게 익힙니다. 어떤 컴포넌트를 써야 하는지, 어떤 파일은 건드리면 안 되는지, 어떤 스타일은 허용되지 않는지, 어떤 변경은 배포 리스크가 큰지 몸소 느끼죠.
AI는 당연히 이런 경험을 해본 적이 없어요.
따라서 중요한 규칙은 명시해야 합니다.
국내 A IT 대기업 프로젝트에서도 설정 파일을 계층적으로 구성했습니다. AI에게 어떤 범위에서 어떤 규칙을 적용할지 알려주는 장치로 주로 활용했고요. User-level에서는 ~/.claude/settings.json과 TypeScript/JDTLS 플러그인을 관리했고, Monorepo-level에서는 프로젝트 단위로 git, pnpm 같은 자동 허용 항목과 공통 Agents & Skills를 관리했습니다. Module-level에서는 특정 모듈 단위로 조건부 Rules, Hooks, Bash/Edit 같은 권한 설정을 적용했습니다.
또, 항상 적용되는 규칙에는 risky-change.md, hitl-checkpoints.md처럼 위험 변경과 사람 개입 지점을 다루는 문서가 포함됐습니다. 조건부 Rules는 Glob 패턴을 활용해 backend, frontend, design-system, testing 영역에 맞게 매핑했습니다. 즉 백엔드 파일을 수정할 때와 프론트엔드 파일을 수정할 때, 디자인 시스템을 건드릴 때와 테스트 코드를 작성할 때 서로 다른 규칙이 적용되도록 만든 셈이죠.
그중 가장 효과가 컸던 것은 design-system Rule이었는데요.
본 프로젝트에서는 정해진 브랜드 컬러를 사용해야 했고, 디자이너와 약속된 스타일대로 화면을 구성해야 했어요. 그런데 초기에는 AI가 겉보기에는 비슷한 화면을 만들더라도, 실제 코드를 보면 공통 컴포넌트를 쓰지 않거나 디자인 시스템 토큰을 따르지 않는 경우가 있었습니다. 그래서 design-system Rule을 만들었고, figma-implementation Skill도 함께 사용됐습니다. 이후 AI가 임의로 색상 코드나 스타일을 만드는 경우가 줄어 화면 구현 결과의 일관성도 꽤 괜찮아졌습니다.
Rules는 실전 개발에서 정말 유용했습니다. 그럴듯한 화면을 치는 수준에서 벗어나, 프로젝트 규칙과 디자인 가이드에 맞는 화면을 만들도록 한 것이니까요.
3장. AI의 역할을 잘게 쪼개기
AI에게 큰 작업을 한 번에 맡기면 시작은 빠릅니다. 하지만 작업이 길어질수록 컨텍스트가 흐려지고, 처음의 목표에서 벗어나거나, 필요한 범위를 넘어 너무 많은 코드를 수정하는 일이 생길 수 있어요. 그래서 본 프로젝트에서는 AI가 맡는 일을 더 잘게 나눴습니다.
이때 사용한 것이 Sub-Agents와 Skills인데요.
Sub-Agents는 특정 역할을 맡는 보조 에이전트입니다. api-designer는 API 설계 관점에서 엔드포인트와 요청·응답 스키마, 기존 API 패턴과의 일관성을 확인합니다. code-reviewer는 변경사항이 코드베이스의 규칙과 맞는지, 위험한 변경은 없는지, 리팩터링 범위가 과하지 않은지 검토하고요. test-writer는 구현된 기능에 필요한 회귀 테스트를 판단하고 테스트 코드를 보강합니다. 반면 Skills는 작업 절차에 가깝습니다.
실제로 특정 채팅 Agent에서 스트리밍 응답이 중간에 끊기는 이슈가 있었을 때도 이 방식이 적용됐습니다. 예를 들어 /bugfix Skill은 단순히 코드를 수정하는 수준이 아니라, 관련 코드를 훑고 증상을 요약한 뒤 프론트의 이벤트 수신부/ 백엔드의 스트림 전달부/ Agent 응답 처리부를 따라가며 원인을 좁히고 문제를 수정했습니다.
수정 후에는 test-writer가 회귀 테스트 코드를 작성했고, code-reviewer가 변경 내용을 다시 검토했습니다. 마지막으로는 /risky-check를 실행해 Python 기반의 risky-change-check 코드를 통해 변경사항 안에 배포 리스크가 있는지 확인합니다. 모든 검증이 통과하면 커밋 메시지 초안까지 생성하도록 했어요.
이렇듯 AI에게 더 많은 일을 맡기기 위해서는, 일을 크게 던지는 것이 아니라 더 잘게 나눠야 합니다. 이게 바로 하네스의 주요 역할 중 하나예요.
4장. 사람 개입이 필요한 순간을 정해두기
AI가 더 많은 작업을 수행할수록, 사람이 개입해야 하는 지점은 더 명확해야 합니다.
모든 코드를 사람이 다시 쓸 필요는 없지만, 반드시 사람이 판단해야 하는 순간은 있어요. 본 프로젝트에서는 이 지점을 HITL, 즉 Human-in-the-Loop 체크포인트로 관리했습니다.
일단 HITL 도메인은 chat, auth, admin, report, agent, data처럼 영향도가 큰 영역을 중심으로 설정했습니다. AI가 이 영역에서 중요한 변경을 시도하면, 작업을 계속 진행하기 전에 사람의 확인을 받도록 해두었습니다.
실제로 이 체크포인트가 불필요한 변경을 막은 적도 있었습니다. 채팅 기능 중 일부를 수정하는 요구사항이 있었는데요. 원래는 데이터베이스와 전혀 관련이 없는 코드만 변경하면 되는 작업이었습니다. 그런데 AI가 작업하는 과정에서 계획에 없던 데이터베이스 스키마 변경을 시도하려는 것이 감지됐고, HITL 체크포인트가 먼저 멈춰 세웠습니다. 사람이 확인해보니 요구사항상 전혀 필요 없는 변경이었어요. 작은 채팅 기능 수정처럼 보이는 작업에서 불필요한 DB 스키마 변경이 들어갔다면, 이후 예상하지 못한 운영 리스크로 이어질 수 있었기에 다행이라고 생각했습니다. 이후 영향도가 큰 변경은 반드시 HITL 체크포인트를 거치도록 했습니다.
AI가 절차를 냅다 건너뛰는 경우도 있었습니다.
예를 들어 기능 개발 시에는 계획, 계획 리뷰, 테스트 코드 작성, 메인 코드 작성, 코드 리뷰, 리스크 평가 같은 단계를 반드시 거쳐야 했습니다. 그런데 Claude Code가 중간에 자의적으로 판단해 코드 리뷰를 건너뛰거나, worktree로 작업 영역을 분리해야 하는데 실제로는 분리하지 않고 진행한 경우가 있었어요. 겉으로는 작업이 정상적으로 진행된 것처럼 보였고요. 하지만 확인해보면 검증 단계가 빠져 있는 등 오류가 많았습니다.
계획 리뷰를 건너뛰면 변경 범위가 틀릴 수 있고, 테스트 코드 작성을 건너뛰면 실제 동작 검증이 빠질 수 있으며, 리스크 평가를 건너뛰면 배포 영향도를 놓칠 수 있기 때문에 Claude Code의 PreToolUse hook 기능을 활용해 현재 단계에서 허용된 작업인지, 선행 단계가 완료됐는지, 작업 영역 분리가 필요한지 등을 검증하도록 했습니다.
프롬프트로 지켜줘라고 요청하는 것과, 실제로 지키도록 만드는 것은 달라요. 실전에서는 후자가 필요합니다. 하네스는 바로 이 차이를 만드는 구조이고요.
AI가 더 많은 일을 하게 될수록, 사람이 매번 눈으로 확인하지 않아도 지켜져야 하는 절차가 생깁니다. 어떤 변경은 멈춰야 하고, 어떤 단계는 반드시 거쳐야 하며, 어떤 결과는 검증을 통과해야 합니다. 코드 생성 능력보다 검증 가능한 흐름이 더 중요해지는 대목입니다.
5장. AI 도구 적재적소에 사용하기
AI 코딩 어시스턴트를 고를 때, 어떤 도구를 쓸 것인가..고민하게 되는데요. 하지만 실제 프로젝트에서 중요한 것은 하나의 정답을 고르는 것이 아니라, 작업의 성격에 따라 도구를 배치하는 것입니다.
프로젝트 초반에는 Cursor를 가장 많이 사용했습니다. 실제로 프로젝트 초반에도 Cursor는 빠르게 코드를 작성하고, 익숙하지 않은 구조를 파악하는 데 많은 도움을 줬습니다.
Cursor는 IDE 안에서 빠른 수정과 탐색에 확실히 강점이 있습니다. 실시간 코드 제안과 자동완성, 코드베이스 문맥 기반 작업, 리팩터링과 반복 수정에 효율적인 도구였고요. 다만 사용량이 늘어나면서 비용 부담이 커졌고, 여러 작업을 병렬로 실행하거나 에이전트처럼 역할을 나눠 작업시키기에는 불편함이 있었습니다.
그래서 이후에는 터미널 기반의 Codex와 Claude Code를 비교했고, 복잡한 코드 이해와 기능 개발에는 Claude Code가 더 잘 맞는다고 판단했습니다. 현재는 Claude Code를 메인으로 사용하되, Codex도 함께 조합해 사용하고 있습니다.
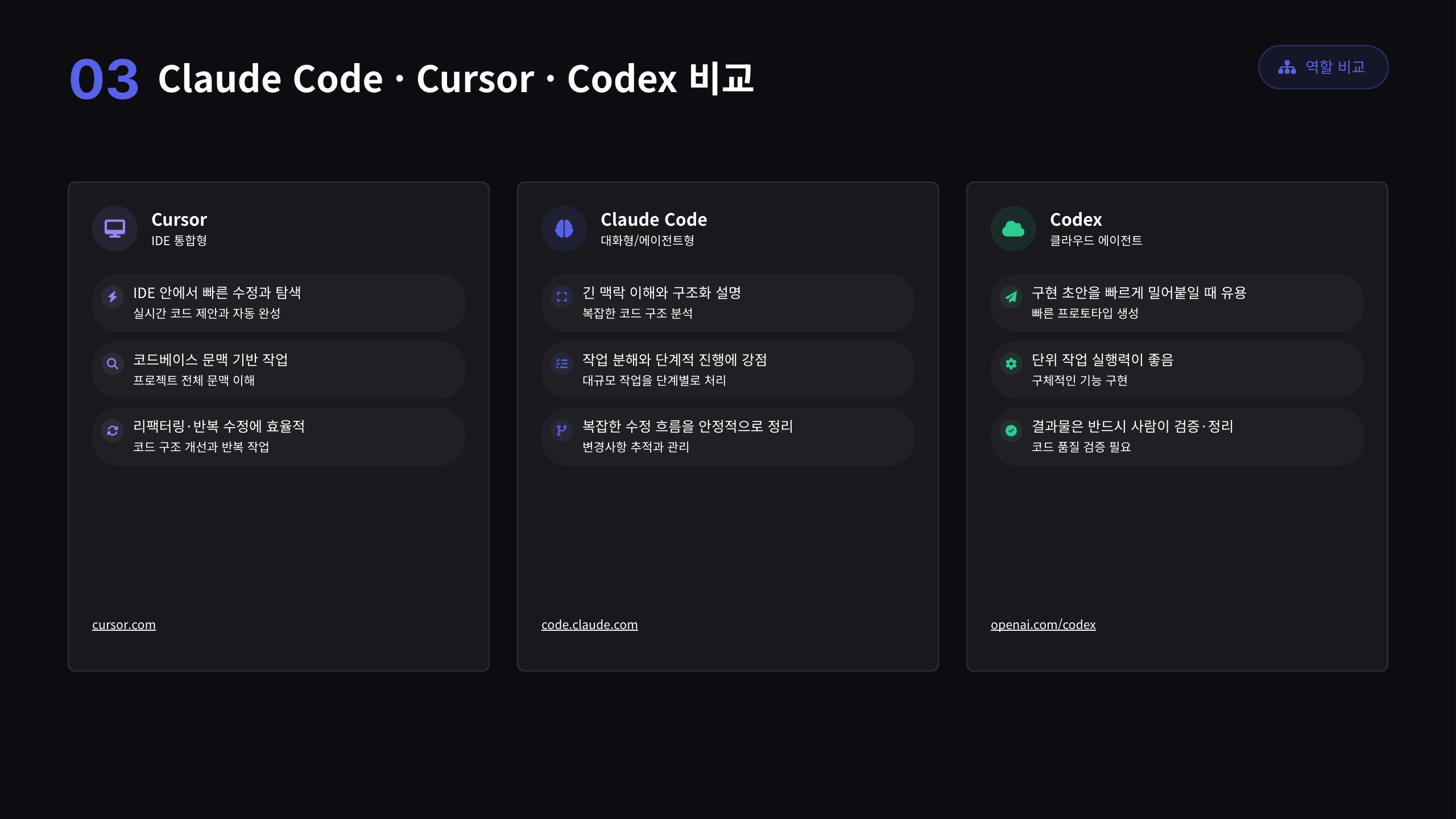
정리하자면,
Cursor는 빠른 탐색과 IDE 안의 반복 수정에 좋았습니다.
Claude Code는 복잡한 코드 이해와 기능 개발 흐름에 적합했습니다.
Codex는 코드 리뷰, 변경사항 검토, 리스크 체크처럼 검토 성격의 작업에 보조적으로 활용했습니다.
마치며. Humans steer, Agents execute
사람은 방향을 정하고, 에이전트는 실행합니다.
AI 코딩 어시스턴트는 개발 속도를 높이고, 낯선 기술 스택에 대한 진입 장벽을 낮추고, 요구사항 변경에 더 빠르게 대응할 수 있게 해줬습니다. 자연어로 의도를 설명하면 코드가 나오고, 오류의 원인을 찾고, 테스트 코드의 초안까지 빠르게 만들 수 있었습니다.
하지만 실전 프로젝트는 빠른 초안만으로 굴러가지 않죠. 결과는 일관되어야 하고, 프로젝트 스타일과 맞아야 하며, 검증 가능해야 합니다. 위험한 변경은 멈춰야 하고, 사람이 최종 책임을 질 수 있는 구조도 필요합니다.
그래서 아마도, 다음 단계는 하네스입니다.
AI는 점점 더 많은 일을 실행할 것입니다. 실행이 늘어날수록 구조는 더 중요해지고요. AI가 우리 팀의 방식으로, 검증 가능한 결과를 반복해서 만들 수 있는가. 이 질문에 답하는 과정에서 AI 코딩은 단순한 도구를 넘어 워크플로우가 됩니다. 그리고 그 워크플로우를 설계하는 일이, 앞으로의 엔지니어링 경쟁력이 될 것입니다.





